Evaluating our machine learning models#
Show code cell content
import warnings
warnings.filterwarnings("ignore")
Show code cell content
import os
from nilearn import datasets
os.environ["NILEARN_SHARED_DATA"] = "~/shared/data/nilearn_data"
datasets.get_data_dirs()
['~/shared/data/nilearn_data', '/Users/emdupre/nilearn_data']
Now that we’ve run a few classifications models, what more could we need to know about machine learning in neuroimaging ? A lot, actually ! Everything that we’ve done to date falls broadly under the umbrella of “feature engineering.” When applying machine learning, however, equally important are (1) the model that we train to generate predictions and (2) how we assess the generalizability of our learned model.
In this notebook, we’ll focus on (2). In particular, we’ll highlight the importance of appropriate cross-validation methods. First, we can look at a recent review [1] showing common cross-validation methods in neuroimaging:
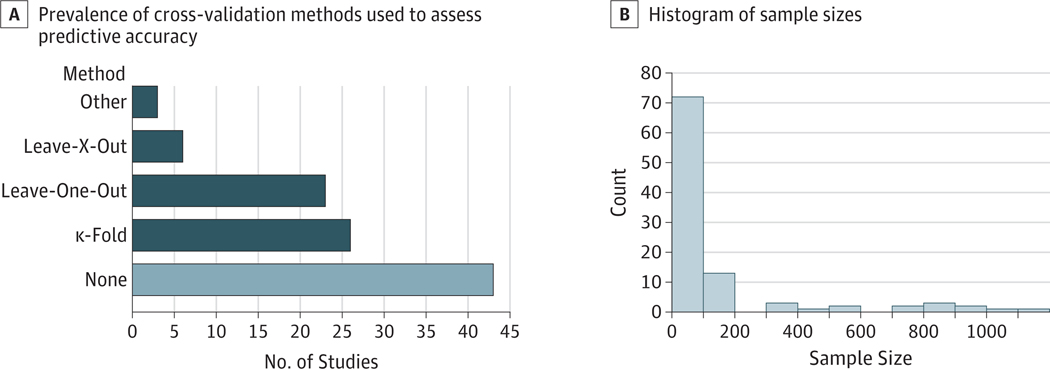
Fig. 3 From [1], depicting results from a review of 100 studies (2017–2019) claiming prediction on fMRI data. Panel A shows the prevalence of cross-validation methods in this sample. Panel B shows a histogram of associated sample sizes.#
As you can see, many neuroscience researchers are not using cross-validation at all !
We will briefly overview why cross-validation is so important to achieve, as well as different strategies for cross-validation that are in use with neuroimaging data.
We then provide examples of appropriate and inappropriate cross-validation within the development_fmri dataset.
One thing to emphasize, here : best practice is always to have a separate, held-out validation set !
This will allow us to make more meaningful statements about our learned model,
but it requires having access to more data.
Why cross-validate ?#
First, let’s formalize the problem that cross-validation aims to solve, using notation from [2].
For \(N\) observations, we can choose a variable \(y \in \mathbb{R}^n\) that we are trying to predict from data \(X \in \mathbb{R}^{n \times p}\). For example, we may have neuroimaging data for 155 participants, from which we are trying to predict their age group as either a child or an adult.
The machine learning problem is to estimate a function \(\hat{f}_{\{ train \}}\) that predicts best \(y\) from \(X\). In other words, we want to minimize an error \(\mathcal{E}(y,\hat{f}(X))\).
The challenge is that we are interested in this error on new, unknown, data. Thus, we would like to know the expectaction of the error for \((y, X)\) drawn from their unknown distribution:
From this we note two important points.
Evaluation procedures must test predictions of the model on held-out data that is independent from the data used to train the model.
Cross-validation procedures that repeating the train-test split many times to vary the training set also allow use to ask a related question: given future data to train a machine learning method on a clinical problem, what is the error that I can expect on new data?
Forms of cross-validation#
Given the importance of cross-validation in machine learning, many different schemes exist. The scikit-learn documentation has a section just on this topic, which is worth reviewing in full. Here, we briefly highlight how cross-validation impacts our estimates in our example dataset.
Testing cross-validation schemes in our example dataset.#
We’ll keep working with the same development_dataset, though this time we’ll fetch all 155 subjects.
Again, we’ll derive functional connectivity matrices for each participant, though this time we’ll only consider the “correlation” measure.
import numpy as np
import matplotlib.pyplot as plt
from nilearn import (datasets, maskers, plotting)
from nilearn.connectome import ConnectivityMeasure
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.svm import LinearSVC
development_dataset = datasets.fetch_development_fmri()
msdl_atlas = datasets.fetch_atlas_msdl()
masker = maskers.NiftiMapsMasker(
msdl_atlas.maps, resampling_target="data",
t_r=2, detrend=True,
low_pass=0.1, high_pass=0.01).fit()
correlation_measure = ConnectivityMeasure(kind='correlation')
pooled_subjects = []
groups = [] # child or adult
for func_file, confound_file, (_, phenotypic) in zip(
development_dataset.func,
development_dataset.confounds,
development_dataset.phenotypic.iterrows()):
time_series = masker.transform(func_file, confounds=confound_file)
pooled_subjects.append(time_series)
groups.append(phenotypic['Child_Adult'])
_, classes = np.unique(groups, return_inverse=True)
pooled_subjects = np.asarray(pooled_subjects)
Show code cell output
[fetch_development_fmri] Dataset found in /Users/emdupre/nilearn_data/development_fmri
[fetch_development_fmri] Dataset found in /Users/emdupre/nilearn_data/development_fmri/development_fmri
[fetch_development_fmri] Dataset found in /Users/emdupre/nilearn_data/development_fmri/development_fmri
[fetch_atlas_msdl] Dataset found in /Users/emdupre/nilearn_data/msdl_atlas
In our classification example, we used StratifiedShuffleSplit for cross-validation.
This method preserves the percentage of samples for each class across train and test splits;
that is, the percentages of child and adult participants in our classification example.
from sklearn.metrics import ConfusionMatrixDisplay
# First, re-generate our cross-validation scores for StratifiedShuffleSplit
strat_scores = []
cv = StratifiedShuffleSplit(n_splits=5, random_state=0, test_size=30)
for train, test in cv.split(pooled_subjects, groups):
connectivity = ConnectivityMeasure(kind="correlation", vectorize=True)
connectomes = connectivity.fit_transform(pooled_subjects[train])
classifier = LinearSVC().fit(connectomes, classes[train])
predictions = classifier.predict(
connectivity.transform(pooled_subjects[test]))
strat_scores.append(accuracy_score(classes[test], predictions))
print(f'StratifiedShuffleSplit Accuracy: {np.mean(strat_scores):.2f} ± {np.std(strat_scores):.2f}')
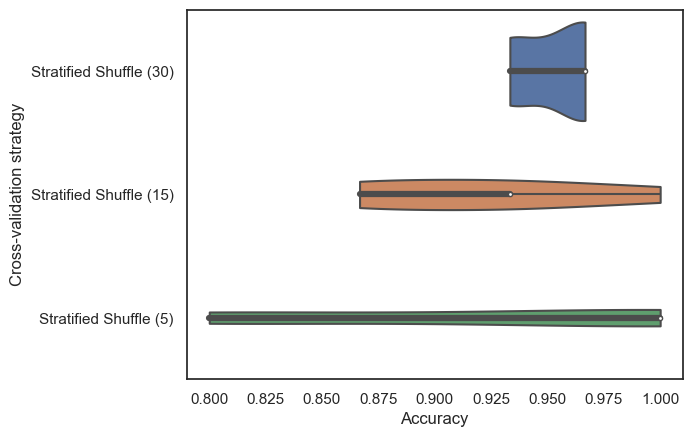
StratifiedShuffleSplit Accuracy: 0.95 ± 0.02
# Then, generate a confusion matrix for the trained classifier
# We'll plot just the last CV fold for now
cm = ConfusionMatrixDisplay.from_predictions(classes[test], predictions)
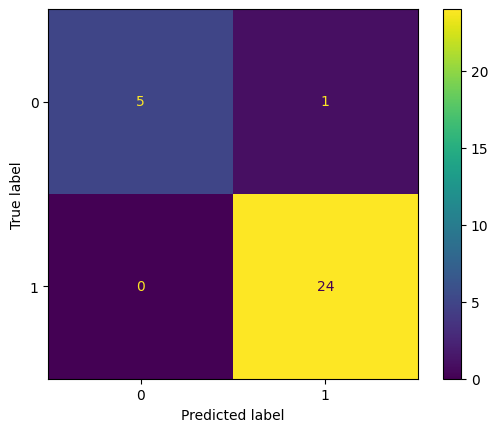
What if we don’t account for age groups when generating our cross-validation folds ?
We can test this by using KFold, which does not stratify by group membership.
# Then, compare with cross-validation scores for ShuffleSplit
from sklearn.model_selection import KFold
kfold_scores = []
cv = KFold(n_splits=5)
for train, ktest in cv.split(pooled_subjects):
connectivity = ConnectivityMeasure(kind="correlation", vectorize=True)
connectomes = connectivity.fit_transform(pooled_subjects[train])
classifier = LinearSVC().fit(connectomes, classes[train])
kfold_predictions = classifier.predict(
connectivity.transform(pooled_subjects[ktest]))
kfold_scores.append(accuracy_score(classes[ktest], kfold_predictions))
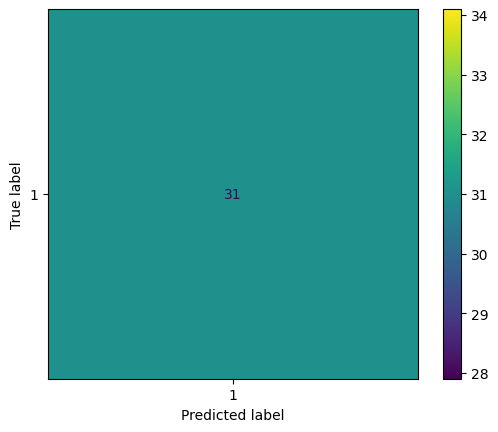
print(f'KFold Accuracy: {np.mean(kfold_scores):.2f} ± {np.std(kfold_scores):.2f}')
KFold Accuracy: 0.77 ± 0.39
# Then, generate a confusion matrix for the trained classifier
# We'll plot just the last CV fold for now
cm = ConfusionMatrixDisplay.from_predictions(classes[ktest], kfold_predictions)
Beyond accuracy: The Receiver-Operator Characteristic (ROC) Curve#
This exercise also shows the limitations of the accuracy metric. It can be useful to look at other metrics, such as the Receiver-Operator Characteristic (ROC) Curve. Note that we’re showing the ROC Curve for our StratifiedShuffleSplit model; our KFold model has an undefined area under the curve, since it only predicts one value !
from sklearn.metrics import auc, RocCurveDisplay
RocCurveDisplay.from_predictions(
classes[test],
predictions,
color="darkorange",
plot_chance_level=True,
)
plt.axis("square")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC curve")
plt.legend()
plt.show()
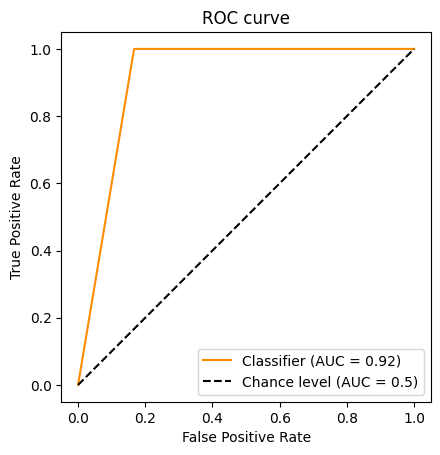
ROC curves can seem a bit harder to interpret than accuracy values, but we can think about them as defining our classifer’s performance in a space of True Positives and False positives.
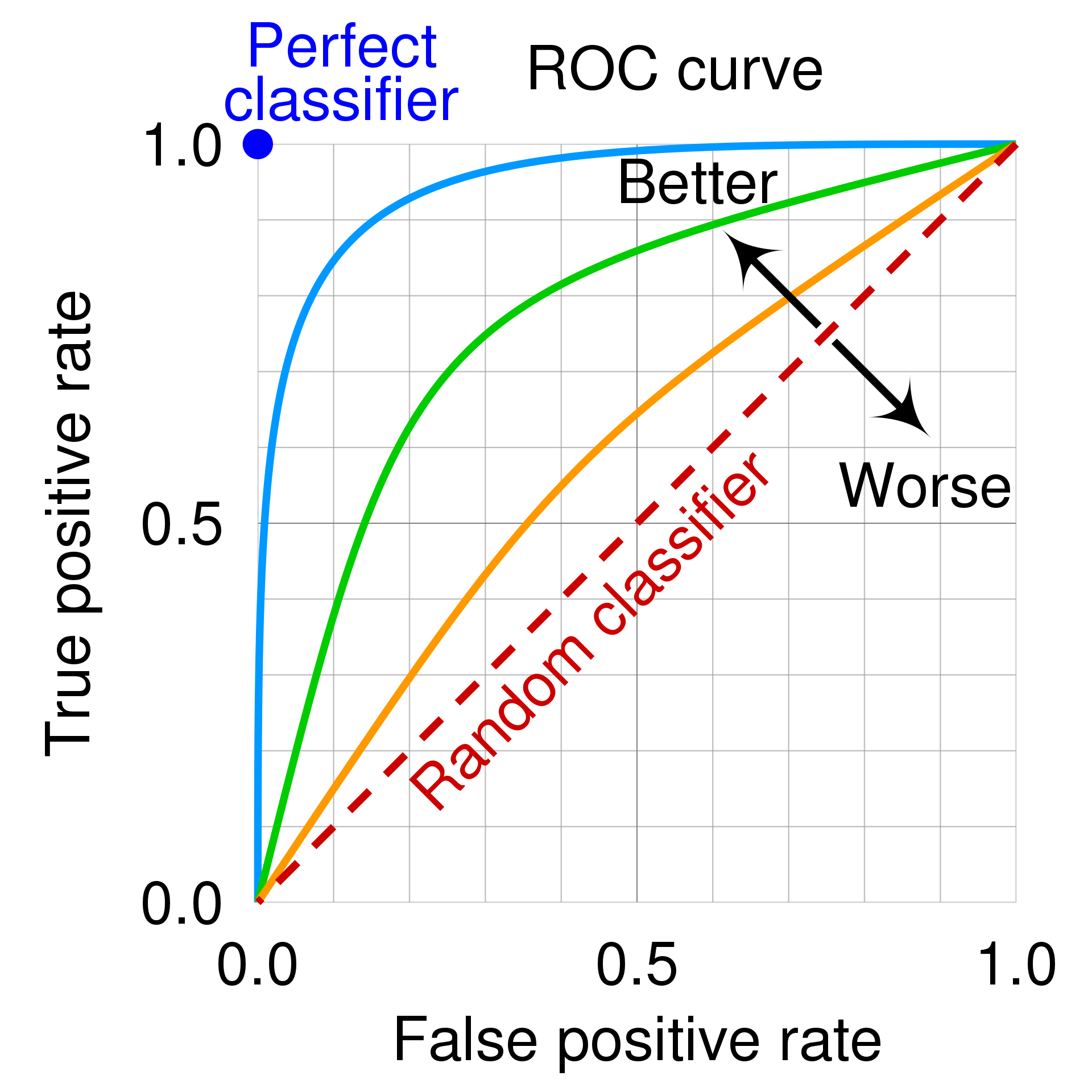
Fig. 4 The ROC space for a “better” and “worse” classifier, from Wikipedia.#
Our ROC curve also provides a useful visualization to look at the variability of our learned model across cross-validation folds !
Show code cell source
tprs = []
aucs = []
mean_fpr = np.linspace(0, 1, 100)
fig, ax = plt.subplots(figsize=(6, 6))
cv = StratifiedShuffleSplit(n_splits=5, random_state=0, test_size=30)
for fold, (train, test) in enumerate(cv.split(pooled_subjects, groups)):
connectivity = ConnectivityMeasure(kind="correlation", vectorize=True)
connectomes = connectivity.fit_transform(pooled_subjects[train])
classifier = LinearSVC().fit(connectomes, classes[train])
viz = RocCurveDisplay.from_estimator(
classifier,
connectivity.transform(pooled_subjects[test]),
classes[test],
name=f"ROC fold {fold}",
alpha=0.3,
lw=1,
ax=ax,
plot_chance_level=(fold == 4), # n_splits - 1
)
interp_tpr = np.interp(mean_fpr, viz.fpr, viz.tpr)
interp_tpr[0] = 0.0
tprs.append(interp_tpr)
aucs.append(viz.roc_auc)
mean_tpr = np.mean(tprs, axis=0)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
std_auc = np.std(aucs)
ax.plot(
mean_fpr,
mean_tpr,
color="b",
label=f"Mean ROC (AUC = %0.2f ± %0.2f)" % (mean_auc, std_auc),
lw=2,
alpha=0.8,
)
std_tpr = np.std(tprs, axis=0)
tprs_upper = np.minimum(mean_tpr + std_tpr, 1)
tprs_lower = np.maximum(mean_tpr - std_tpr, 0)
ax.fill_between(
mean_fpr,
tprs_lower,
tprs_upper,
color="grey",
alpha=0.2,
label=r"± 1 std. dev.",
)
ax.set(
xlim=[-0.05, 1.05],
ylim=[-0.05, 1.05],
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title=f"Mean ROC curve with variability",
)
ax.axis("square")
ax.legend(loc="lower right")
plt.show()
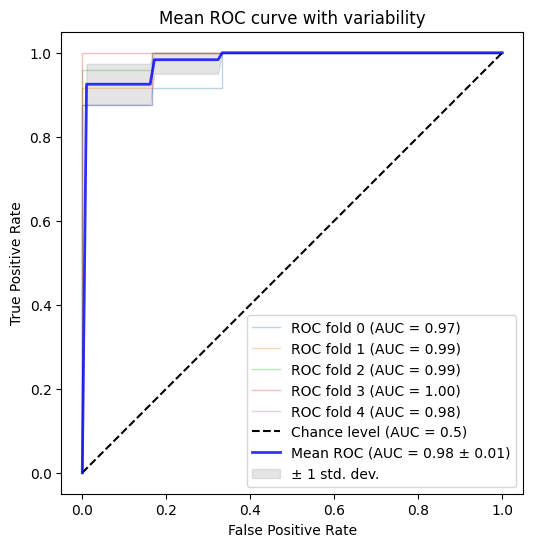
Small sample sizes give a wide distribution of errors#
Another common issue in cross-validation is when we only have access to small test set.
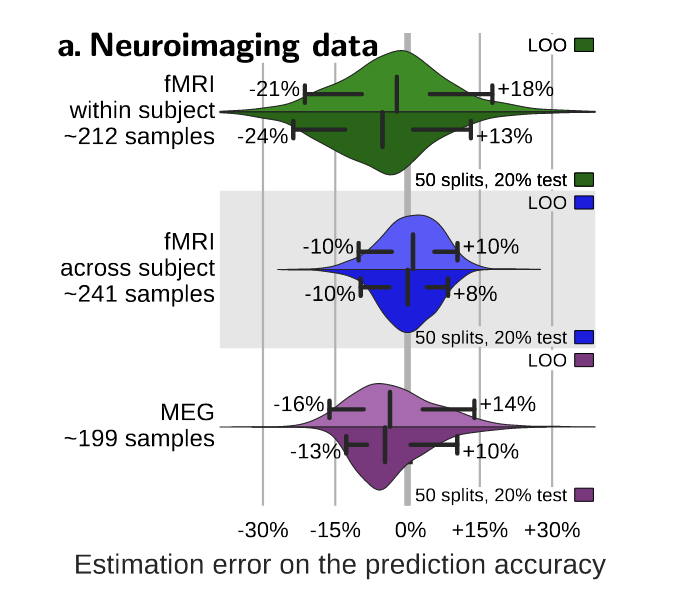
Fig. 5 From [3], this plot shows the distribution of errors between the prediction accuracy as assessed via cross-validation (average across folds) and as measured on a large independent test set for different types of neuroimaging data. Accuracy is reported for two reasonable choices of cross-validation strategy: leave-one-out (leave-one-run-out or leave-one-subject-out in data with multiple runs or subjects), or 50-times repeated splitting of 20% of the data. The bar and whiskers indicate the median and the 5th and 95th percentile.#
The results show that these confidence bounds extends at least 10% both ways; that is, there is a 5% chance that it is 10% above the true generalization accuracy and a 5% chance this it is 10% below. This wide confidence bound is a result of an interaction between
the large sampling noise in neuroimaging data and
the relatively small sample sizes that we provide to the classifier.
We can replicate this idea by systematically decreasing the size of our test set, first to 15 participants.
from sklearn.metrics import ConfusionMatrixDisplay
# med test set StratifiedShuffleSplit
med_strat_scores = []
cv = StratifiedShuffleSplit(n_splits=5, random_state=0, test_size=15)
for train, test in cv.split(pooled_subjects, groups):
connectivity = ConnectivityMeasure(kind="correlation", vectorize=True)
connectomes = connectivity.fit_transform(pooled_subjects[train])
classifier = LinearSVC().fit(connectomes, classes[train])
predictions = classifier.predict(
connectivity.transform(pooled_subjects[test]))
med_strat_scores.append(accuracy_score(classes[test], predictions))
print(f'Medium StratifiedShuffleSplit Accuracy: {np.mean(med_strat_scores):.2f} ± {np.std(med_strat_scores):.2f}')
Medium StratifiedShuffleSplit Accuracy: 0.92 ± 0.05
Then to 5.
from sklearn.metrics import ConfusionMatrixDisplay
# small test set StratifiedShuffleSplit
small_strat_scores = []
cv = StratifiedShuffleSplit(n_splits=5, random_state=0, test_size=5)
for train, test in cv.split(pooled_subjects, groups):
connectivity = ConnectivityMeasure(kind="correlation", vectorize=True)
connectomes = connectivity.fit_transform(pooled_subjects[train])
classifier = LinearSVC().fit(connectomes, classes[train])
predictions = classifier.predict(
connectivity.transform(pooled_subjects[test]))
small_strat_scores.append(accuracy_score(classes[test], predictions))
print(f'Small StratifiedShuffleSplit Accuracy: {np.mean(small_strat_scores):.2f} ± {np.std(small_strat_scores):.2f}')
Small StratifiedShuffleSplit Accuracy: 0.92 ± 0.10
Then we can compare the distributions of these accuracy scores for each cross-validation scheme:
import seaborn as sns
sns.set_theme(style='white')
ax = sns.violinplot(
data=[strat_scores, med_strat_scores, small_strat_scores],
orient='h',
cut=0
)
ax.set(
yticklabels=[
'Stratified Shuffle (30)',
'Stratified Shuffle (15)',
'Stratified Shuffle (5)'
],
ylabel='Cross-validation strategy',
xlabel='Accuracy'
);
Avoiding data leakage between train and test#
In [4], Varoquaux and colleagues evaluated the impact of different cross-validation schemes on derived accuracy values. We reproduce their Figure 6 below.
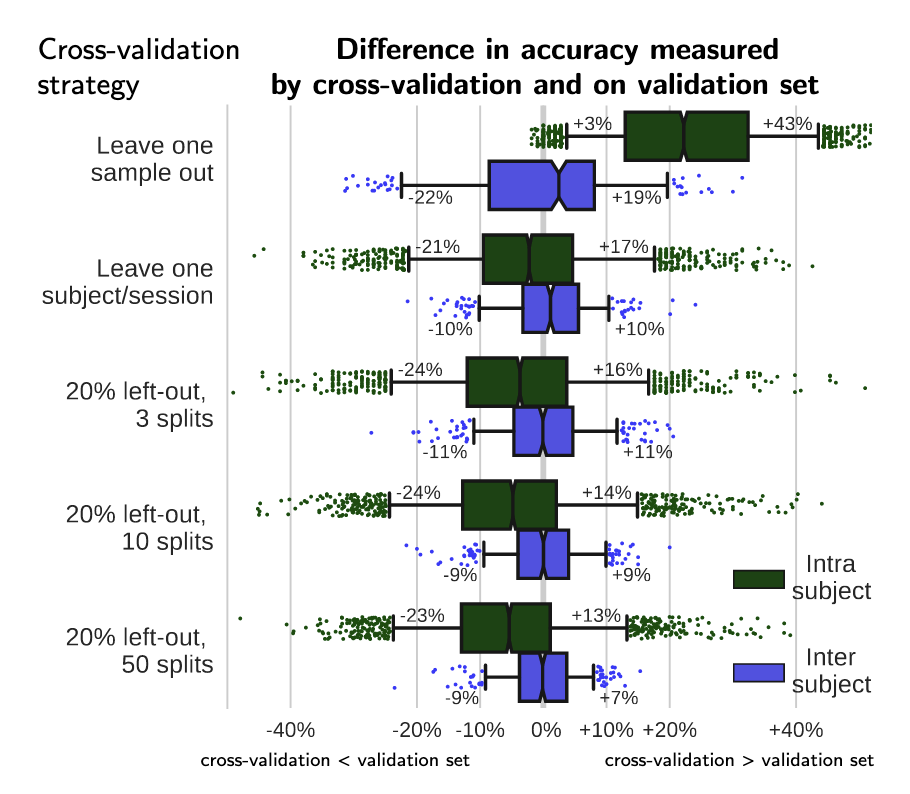
Fig. 6 From [4] shows the difference in accuracy measured by cross-validation and on the held-out validation set, in intra and inter-subject settings, for different cross-validation strategies: (1) leave one sample out, (2) leave one block of samples out (where the block is the natural unit of the experiment: subject or session), and random splits leaving out 20% of the blocks as test data, with (3) 3, (4) 10, or (5) 50 random splits. For inter-subject settings, leave one sample out corresponds to leaving a session out. The box gives the quartiles, while the whiskers give the 5 and 95 percentiles.#
We see that cross-validation schemes that “leak” information from the train to test set can give overly optimistic predictions. For example, if we leave-one-session-out for predictions within a participant, we see that our estimated prediction accuracy from cross-validation is much higher than our prediction accuracy on a held-out validation set. This is because different sessions from the same participant are highly-correlated; that is, participants are likely to show similar patterns of neural responses across sessions.
In our dataset, this isn’t a clear problem, since each participant was only sampled once. It is, though, something to stay aware of !
# Compare with cross-validation scores for leave-one-subject-out
from sklearn.model_selection import LeaveOneOut
loo_scores = []
cv = LeaveOneOut()
for train, test in cv.split(pooled_subjects):
connectivity = ConnectivityMeasure(kind="correlation", vectorize=True)
connectomes = connectivity.fit_transform(pooled_subjects[train])
classifier = LinearSVC().fit(connectomes, classes[train])
predictions = classifier.predict(
connectivity.transform(pooled_subjects[test]))
loo_scores.append(accuracy_score(classes[test], predictions))
print(f'Leave-One-Out Accuracy: {np.mean(loo_scores):.2f} ± {np.std(loo_scores):.2f}')
Leave-One-Out Accuracy: 0.95 ± 0.21
- 1(1,2)
Russell A Poldrack, Grace Huckins, and Gaël Varoquaux. Establishment of best practices for evidence for prediction: a review. JAMA psychiatry, 77(5):534–540, 2020.
- 2
Max A Little, Gaël Varoquaux, Sohrab Saeb, Luca Lonini, Arun Jayaraman, David C Mohr, and Konrad P Kording. Using and understanding cross-validation strategies. perspectives on saeb et al. GigaScience, 6(5):gix020, 2017.
- 3
Gaël Varoquaux. Cross-validation failure: small sample sizes lead to large error bars. Neuroimage, 180:68–77, 2018.
- 4(1,2)
Gaël Varoquaux, Pradeep Reddy Raamana, Denis A Engemann, Andrés Hoyos-Idrobo, Yannick Schwartz, and Bertrand Thirion. Assessing and tuning brain decoders: cross-validation, caveats, and guidelines. NeuroImage, 145:166–179, 2017.